Unlock Corporate Data: Building a Secure Local AI for $20/mo
by Max Vornovskykh | January 14, 2026 12:25 pm
In over twenty years of business, long before AI we operated under a fundamental truth: knowledge is the most valuable asset. Across hundreds of projects, our team has accumulated extensive QA expertise. Yet, as we scaled, we encountered the classic enterprise paradox – the more knowledge you gather, the harder it becomes to access it when you need it most.
For years, the task of collecting, organising, and retrieving knowledge came with a heavy asterisk. It was manual, inconsistent, and often relied on human memory.
Then came the COVID-19 pandemic. It forced a transition to hybrid work that initially felt like a constraint but revealed a hidden opportunity. Suddenly, every architectural decision, every debugging session, and every client negotiation had digital footprints.
Combined with the explosive maturing of LLMs (Large Language Models), we saw a chance to solve a problem that had plagued us (and the entire industry) for years. We set out to build a self-updating Corporate Brain – a system that transforms the information flowing through daily calls into tangible data pieces.
Key numbers: the system currently processes 50–60 recordings/day, and our tiered S3 approach keeps monthly storage around $20 even at ~65 videos/day (~350MB each).
This article details how we engineered a secure, event-driven AI pipeline to automate knowledge management, and how we applied our core QA philosophy to test the “untestable” world of generative AI.
The 4 Constraints of Traditional Knowledge Management
We analyzed why corporate knowledge fails to stick, identifying four specific friction points and how our AI solution resolves them:
- The Documentation Tax
Problem: Engineers waste hours manually summarizing 45-minute meetings.
Solution: Automated video scraper and knowledge extractor services remove manual overhead. - The Silo Effect
Problem: Expertise remains trapped in individual heads, requiring multiple meetings just to locate status updates.
Solution: A centralized semantic database makes conversation history searchable. - The Onboarding Gap
Problem: New hires lack historical context on long-running projects. How can AI help with onboarding?
Solution: Contextual synthesis allows new members to query past project data for instant briefs. - Situational Blindness
Problem: Real-time awareness is impossible when data is buried in reports.
Solution: Automated situational awareness provides a holistic view of portfolio health.
It wasn’t enough to make a ChatGPT wrapper, as it would introduce privacy risks. We had to design a system architecture for processing internal meeting videos without using public APIs.
That’s how we ended up with a local LLM knowledge base that was secure, scalable, and deeply integrated into our ecosystem. Our solution currently processes 50-60 meeting recordings per day. It transforms raw video into searchable, analysed knowledge assets, tagging them and storing them in our secure corporate environment.
How We Made AI Work
When approaching a task like that, the common question is getting the best tech stack for a secure, self-hosted AI transcription service. Here’s what we did.
To handle the heavy lifting of video processing, we adopted Event-Driven Architecture. This meant utilising RabbitMQ to orchestrate communication between services, ensuring loose coupling. This way, our AI worker-services scaled independently of the ingestion layer and handled spikes in meeting volume without degraded performance.
Here is how the data flows through our Corporate Brain:
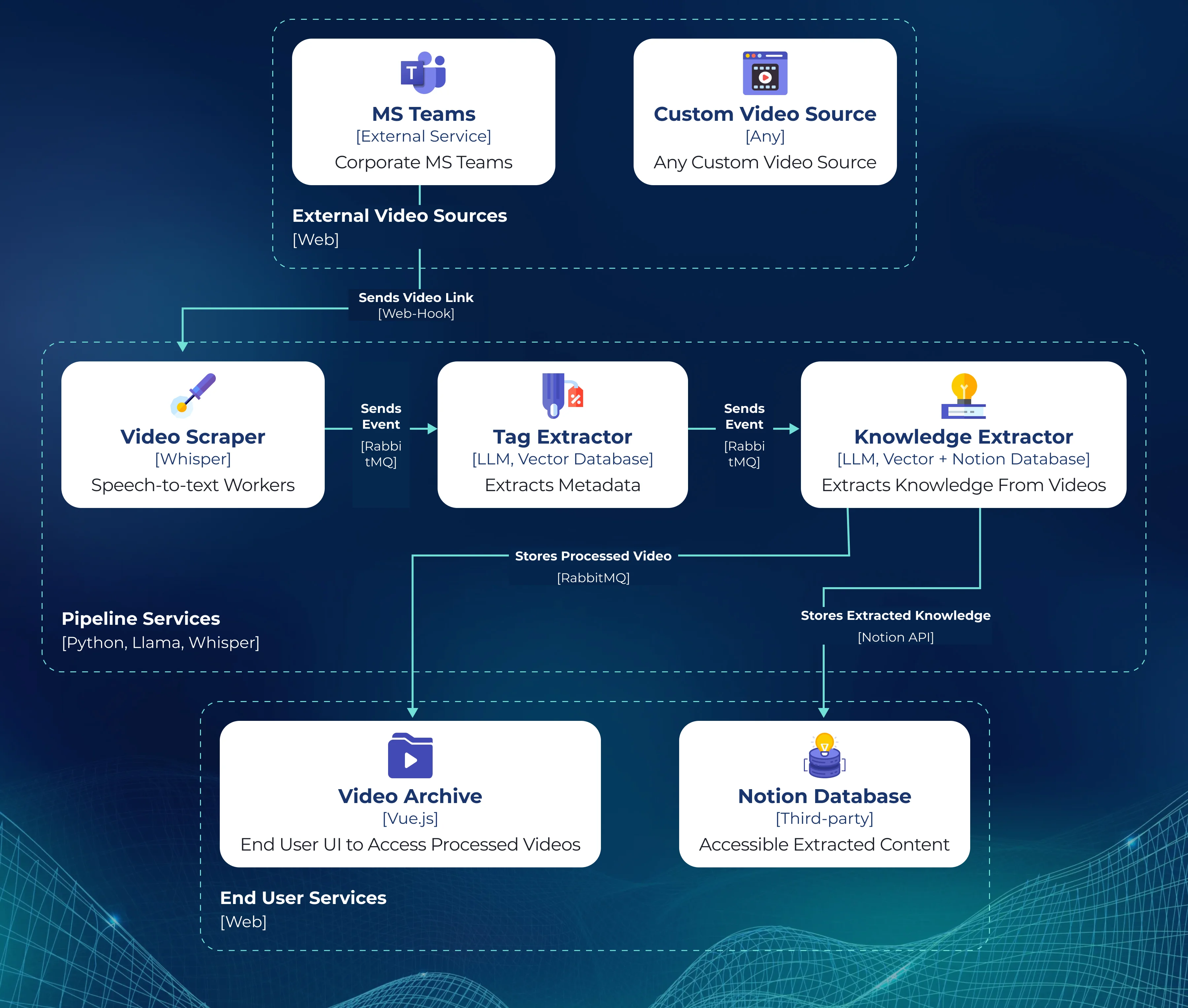
The Ingestion Layer (MS Teams Bot):
- Our custom bot automatically joins chats and monitors meeting guidelines.
- It acts as the interface for the user, dropping automatic summaries into chats and allowing employees to “interrogate” the video content via Q&A.
The Video Scraper (Whisper):
- Detects speaker language and diarises the audio (injecting speaker names).
- Transcribes content in three languages using local instances of the Whisper model.
- Ensures secure raw audio processing within our perimeter.
The Semantic Engine (Tag & Knowledge Extractors):
- This is where the magic happens. Using quantised LLaMA 3.1 models, we extract metadata, identify key discussion points, and isolate action items.
- We don’t just summarise – we extract structured knowledge based on predefined categories to feed our database.
The Archive:
- A custom Vue.js front-end provides a YouTube-like experience for corporate content, complete with search and ACL-based access control.
Notion Database:
- A place where we store and collect knowledge and make it available to the employees in a curated format.
Technical Decisions
Cost-Efficient Storage Strategy
Video data is heavy. To make this financially viable, we implemented a tiered storage strategy on AWS S3:
- Active Storage (S3 Standard): Holds recent content (~500 GB fixed).
- Archive Storage (S3 Glacier): Automatically ingests files via lifecycle policies for long-term retention.
- The Result: Even at ~65 videos/day (~350MB each), monthly storage remains around ~$20.
Local LLMs vs Public APIs (Security First)
As a QA company handling sensitive client data, sending transcripts to public APIs was not an option. To ensure that no sensitive data leaves our infrastructure, we leverage local LLMs (LLaMA 3.1) and local transcription models. Additionally, because access is enforced via ACL-based controls in the archive UI, only authorized teams can access recordings and related knowledge, ensuring security.
Testing the Untestable: AI Quality Assurance
This is where our DNA as a QA company played a pivotal role. Building an AI demo is easy, but building a reliable system and putting it into production is much harder. The challenge with GenAI is non-determinism – how do you evaluate if the knowledge is extracted properly, summaries are relevant, and key points are actually key?
When choosing QA strategies for non-deterministic LLM outputs, our team leverages manual effort[1] combined with the latest methodologies. This one was not only a development project but a full R&D initiative focused on AI Testing & Evaluation Methodologies. We implemented:
- Golden Truth Datasets
We created human-verified baselines for summaries and tag extraction to benchmark our models. - LLM-as-a-Judge
We integrated automated evaluation steps into our CI/CD pipeline using Langfuse. We use a superior model to grade the output of our production models against quality metrics (coherence, relevance, and hallucination). - Observability
We track system prompts and model performance in real-time to detect drift. - Dashboards
We set up a real-time evaluation of token, cost, and time expenditure.
This approach ensures that as we upgrade our models, we don’t silently degrade the quality of our insights.
Our QA team had done this several times for large, modern projects, so this part posed no difficulty for us – it simply allowed us to master a couple of new tools and approaches, which was, of course, very useful and interesting.
The Vision: From Repository to Active Intelligence
What we have built solved the problem of data capture and retrieval. The next phase is transforming this data into Active Intelligence.
Our next planned features include:
The Knowledge Graph
We are moving beyond linear search to a graph-based model connecting Topics→People→Projects→Decisions. This will allow us to visualise hidden dependencies between teams and instantly identify the true subject matter experts within the organisation.
Organisational Health Monitoring
By analysing sentiment and discussion dynamics over time, the system will act as an early warning signal for burnout, conflict, or project gridlock. This moves HR and management from reactive problem-solving to proactive culture management.
The AI Mentor
Imagine a new Junior QA Engineer joining a complex project. Instead of reading documentation for a week, they can ask the Corporate Brain: “Give me a 10-minute summary of the architectural decisions made regarding the payment gateway in the last 6 months”. This drastically reduces ramp-up time.
Conclusions: Key Takeaways for Tech Leaders
If you are considering building your own Corporate Brain, here is our advice from the trenches:
- Start with infrastructure, not models. Your event-driven architecture, queues, and storage policies are what make the system viable.
- Privacy is a must-have, so design for local processing from Day 1. It is the only way to safely scale knowledge management in a client-service business.
- Do not blindly trust the LLM. Build Golden Datasets and automate the evaluation of your AI outputs. This is the difference between a toy and a tool.
This project has served a dual purpose: it has given our leadership unprecedented visibility into our operations, and it has served as a proving ground for our engineers to master the testing of event-based AI systems. We are now applying these advanced competencies to our client projects, ensuring we remain a quality frontrunner in AI.
Whenever you’re working on internal AI projects or looking for an experienced team to ensure quality for a customer-facing product, we can provide tailored QA support. Find cooperation details at the dedicated page[2].
 [3]
[3]Learn more from QATestLab


Related Posts:
- leverages manual effort: https://blog.qatestlab.com/2025/09/10/when-ai-will-replace-manual-testers/
- dedicated page: https://go.qatestlab.com/4sFcFd7
- [Image]: https://go.qatestlab.com/4sFcFd7
- AI Test Case Maintenance: 400 Cases, 4 Agents, Proven Results: https://blog.qatestlab.com/2026/03/24/ai-test-case-maintenance-400-cases-4-agents-proven-results/
- 42% Less Trust? The Truth About AI Workslop: https://blog.qatestlab.com/2026/02/24/the-truth-about-ai-workslop/
- E-Show Madrid 2025: Accessibility as a Key Challenge: https://blog.qatestlab.com/2025/11/13/e-show-madrid-2025-accessibility-as-a-key-challenge/
Source URL: https://blog.qatestlab.com/2026/01/14/secure-local-ai-for-corporate-data/